While preparing a presentation on how immigration, settlement, citizenship and multiculturalism worked together to facilitate integration, I accessed a broad range of the IRCC operational datasets on the government’s Open Data website. Intrigued by what was available and what was not, I reviewed all 227 unique datasets.
IRCC has, to its credit, invested considerable resources in these datasets for both internal and external use, having the fifth largest number of datasets on Open Data (excluding Statistics Canada). Moreover, these datasets are among the most widely used: 11 of the top 25 government datasets downloaded are from IRCC (April 2017).
IRCC demonstrated considerable flexibility and agility in the creation of datasets with respect to the recent wave of Syrian refugees, and the introduction of monthly operational statistics for key programs.
Part of my motivation was to assess the long-standing weaknesses in citizenship datasets, reflecting the relative lower priority of the citizenship program, and make recommendations for improvements.
Not surprisingly, the datasets reflect IRCC’s overall management emphasis on immigration as well as stakeholder demand: permanent and temporary resident datasets are 93.5 percent of the total. The datasets include:
- Permanent residents (immigrants: economic, family and refugee classes): 110 datasets of 47.6 percent of the total.
- Temporary residents (Temporary Foreign Worker Program: includes agricultural workers, live-in caregivers and others; International Mobility Program: includes those admitted under international services agreements like NAFTA, those under “Canadian Interests,” primarily under youth work exchange program and spousal employment; international students): 106 datasets or 45.9 percent.
- Citizenship and passport: Six datasets or 2.6 percent.
- Settlement services: Nine datasets or 3.9 percent.
IRCC datasets can be divided into four categories: ongoing and published on a regular basis (80.5 percent), archived or historical datasets (16.5 percent) and specialized datasets pertaining to international students (2.2 percent).
The majority are updated annually (54.1 percent), followed by the recent introduction of monthly reports (21.6 percent), quarterly (9.1 percent) and other (15.2 percent). Monthly and quarterly reports focus on operational data: the number of applications, approvals, approval rate and inventory.
Permanent and Temporary Residents
The comprehensive datasets for permanent and temporary residents include information regarding program and category, country of origin (whether processing source area, country of citizenship or country of birth), gender and age. Table 1 summarizes this information with most datasets having several variables (e.g., gender and age). Given the shared federal-provincial jurisdiction for immigration, and the increased and active role of the provinces in selection (i.e., the Provincial Nominee Program), it is no surprise that the majority of permanent resident datasets are broken down by province (52.7 percent), with 31.8 percent at the national level. To assist the planning and programmes of municipalities and service provider organizations for settlement services (integration), ten percent are at the Census Metropolitan Area (CMA) level, with a further 4.5 percent at the Census District (CD) level.
Given the shared federal-provincial jurisdiction for immigration, and the increased and active role of the provinces in selection (i.e., the Provincial Nominee Program), it is no surprise that the majority of permanent resident datasets are broken down by province (52.7 percent), with 31.8 percent at the national level. To assist the planning and programmes of municipalities and service provider organizations for settlement services (integration), ten percent are at the Census Metropolitan Area (CMA) level, with a further 4.5 percent at the Census District (CD) level.
In terms of immigration class, over one-quarter are for refugees (27.3 percent), 21.8 percent for economic class, and 1.8 percent for family class, with 49.1 pertaining to all classes.
For temporary residents, who cannot access settlement services, the majority (60.4 percent) are at the national level, 34 percent at the provincial level, and 4.7 percent at the CMA level.
By program, datasets for international students form 23.6 percent, IMP and TFWP each at 21.8 percent and other ten percent, with 22.7 percent pertaining to all programs.
By and large, these datasets are coherent and consistent, with any variation reflecting program needs and a balance between the overall picture and greater detail (e.g., top 10 for refugees, top 20 for IMP or top 50 for students or all (various) countries of birth or citizenship).
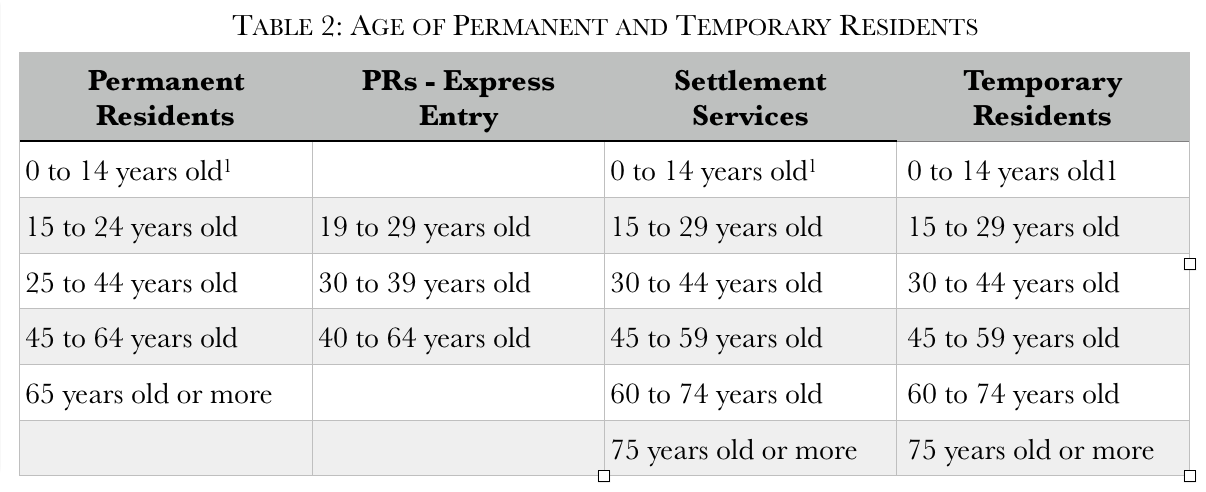
However, as shown in Table 2, the main difference concerns age data, with permanent residents focused more on younger immigrants, compared to temporary residents with a relatively greater focus on older workers. The difference in age cohorts between all permanent residents and those admitted under Express Entry likely has a policy justification. However, it is hard to understand the policy rationale for settlement services using the temporary resident breakdown given that only permanent residents can access these services. IRCC may wish to review whether there is a need for greater consistency and coherence regarding the age cohorts.
Citizenship, Passport and Settlement Services
There are only six datasets for citizenship (including one for passport) and nine for settlement services (three general, six for refugees). This reflects a number of reasons:
- Citizenship has always been a secondary priority for IRCC at both the political and official levels. The program is under-funded and under-managed, as seen in the large and repeated fluctuations in the number of applications and new citizens, in sharp contrast to the number of new permanent residents which is more tightly managed to deliver on the annual levels plan (Chart 1);
- The provinces have no role in citizenship and thus no data demands. Immigration stakeholders have limited interest in citizenship as they focus on immigration and refugee issues;
- Passport is a new program to IRCC (previously was with Global Affairs Canada), with similarly low interest with outside stakeholders beyond basic operational data; and,
- Service provider organizations (SPOs) and others that are interested is settlement services data have a wide range of useful permanent resident data that assists them in planning and operations. IRCC has responded to the needs of SPOs by providing general refugee settlement datasets as well as specific ones for Syrian refugees.
Table 3 lists these datasets:
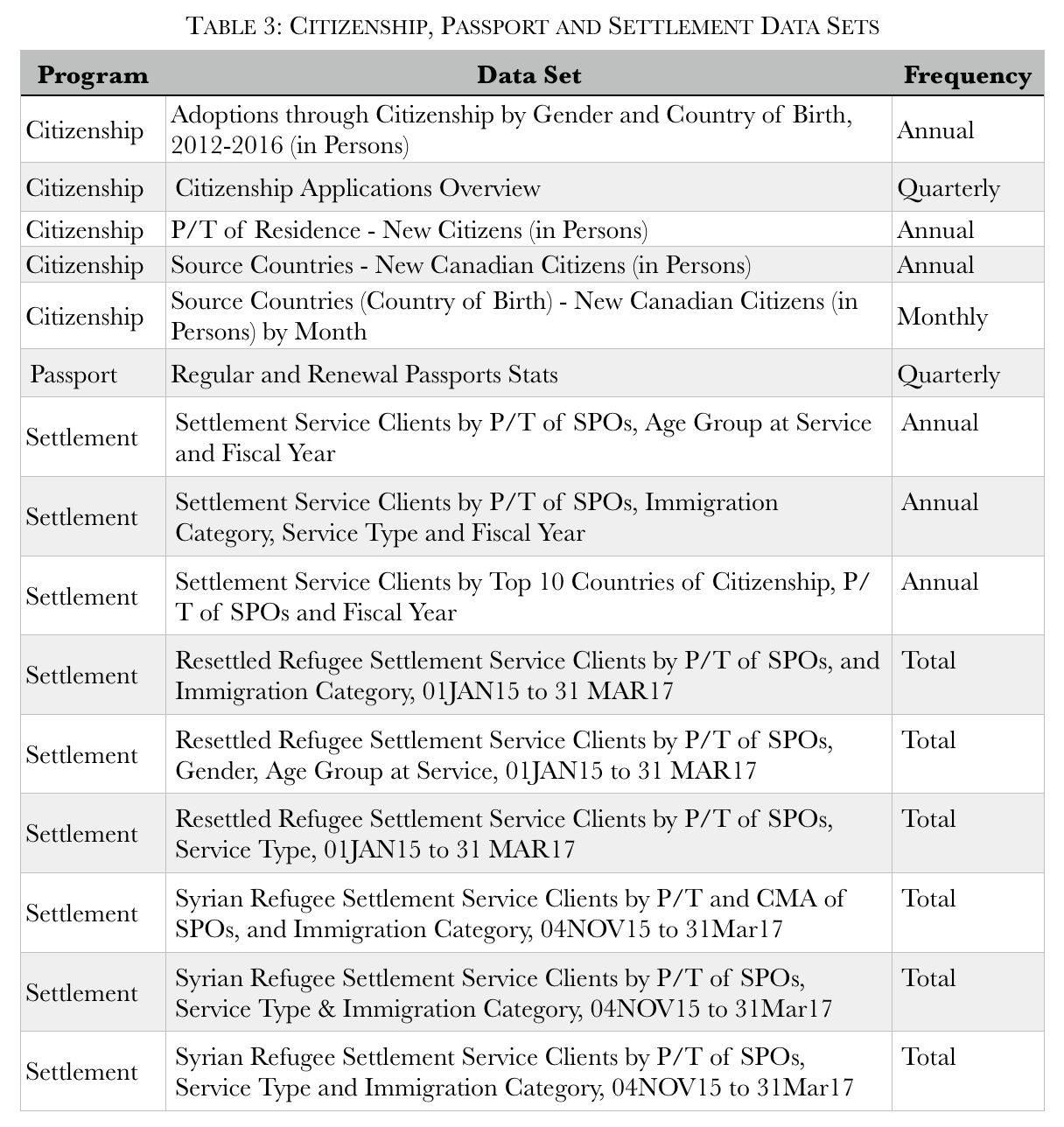
Moreover, these are more limited than other datasets. Annual permanent and temporary resident provide ten year data, adequate to assess trends and changes. In contrast, annual citizenship data covers only five years, settlement services data only two years and passport processing data is not even presented on a full-year basis, making it impossible to assess trends and the impact of policy and program changes. Citizenship datasets are even more limited with no gender and age breakdowns.
They are also updated less frequently than other datasets. Monthly datasets for permanent and temporary residents and settlement services include April 2017 at the time of writing (14 June); citizenship only until February 2017, and passport until December 2016.
Concluding observations
As noted, IRCC has invested considerable resources in developing and maintaining these datasets. In doing so, it has naturally enough reinforced its main focus on immigration statistics, responding to overall stakeholder interests, with minimal attention to citizenship.
The datasets appear to have grown organically as program changes created needs for new datasets. There appears to be potential to review the number and type to see if some datasets are no longer needed or duplicative (e.g., the introduction of monthly datasets may make quarterly ones necessary, are csv versions needed in addition to xls?).
Another area for improvement with respect to provincial datasets is to ensure that these all include national totals by program, as there is currently some inconsistency (e.g., Transition from Temporary Resident to Permanent Resident Status – Quarterly IRCC Updates tables versus the “Facts and Figures” series for both permanent and temporary residents).
Other areas for improvement at the Open Data level include, particularly those that are likely within IRCC control:
- Order the dataset groupings alphabetically as it currently appears random, with related sets not grouped together;
- Review grouping titles for clarity, particularly “Quarterly Updates” as the vast majority of datasets listed are a mix of annual and quarterly data;
- Review all data set titles for consistency (e.g., temporary resident facts and figures are numbered, permanent residents are not; set a standard sequence: program/category then geography, then specific variables such as gender, age, education etc.; inclusion or not of ‘Canada’ in title; indicate specific immigration class if appropriate);
- Advocate with other departments for a wider field for data set descriptions (appears to be only 37 characters) to make these more readable and shorten the wasted space of the titles for other fields (type, format, language, links);
- Advocate for more than 10 dataset groupings per web page to minimize clicks.
My particular focus, however, is with respect to citizenship.
The lack of attention to citizenship, seen operationally in the wide swings of application and new citizens, requires greater management focus and attention. While IRCC has been very helpful in the provision of special runs, more comprehensive citizenship datasets on Open Data are needed. IRCC should ensure a minimum degree of consistency with permanent and temporary resident datasets that would help flag operational and policy concerns. For citizenship, passport, and settlement services, these would include:
- 10-year time series data for citizenship and settlement services;
- 1947-2016 long-term citizenship data (new citizens);
- gender breakdown for citizenship (not just for adoptions), passport and settlement services (not just for refugees);
- age breakdown for citizenship and passport, using the permanent resident age groups; and,
- monthly citizenship applications by country of birth, not just monthly number of new citizens.
Should resources permit, a number of additional citizenship datasets should be considered to provide a more comprehensive understanding of how well the program is working with respect to integration and reinforcing the immigrant-to-citizen transition:
- Annual data on the number and percentage of immigrants who have taken up citizenship within six years of landing in order to assess the recent naturalization rate, not the overall one that IRCC cites in its performance reports and elsewhere. While a target of 70 percent naturalization within six years of landing is proposed, more analysis might suggest a different target. Having this data collected and reported would inform the establishment of a meaningful performance standard; and,
- Annual breakdown by immigration class of new citizens and approval rates by gender to assess the impact on each class of citizenship policies.
Given the importance of immigration, settlement, citizenship and multiculturalism to integration of newcomers and their children, good and comprehensive data is central to evidence-based policy making. IRCC has again commendably invested in such data with respect to immigration data but should address the above mentioned gaps in citizenship data to strengthen the management and oversight of the citizenship program.

