In the dark: The cost of Canada’s data deficit
2019/01/28 Leave a comment
This incredibly valuable investigative reporting. I have excerpted a few of the sections I found most interesting but the entire article is worth a good read, and I look forward to future segments in this series.
I use StatsCan and other data frequently and generally find I can find what I need, or an alternate way to identity issues and trends. So I do have some sympathy for StatsCan Head Anora’s comments that sometimes researchers don’t try hard enough (e.g., see my critique of Karen Robson: Why won’t Canada collect data on race and student success?, weak to non-existent municipal diversity statistics can be found in census occupation group data).
But the example of birth statistics is where I cam up short. The vital statistics agencies do not capture visible minority data or accurate residency data, and do not verify identity documents of the parents. All of which mean, in addition to the all important health-related differences, that births to non-residents are drastically undercounted by StatsCan (in the end, I found better if imperfect numbers from hospital financial statistics: Hospital stats show birth tourism rising in major cities).
I look forward to their analysis of the data available on the government’s open data website as I did an analysis a few years back on the IRCC datasets, the most comprehensive ones available, but where timeliness is becoming an issue (IRCC Datasets: What they say about government priorities):
….
And yet, in fields ranging from public health to energy economics to the labour force to the status of children with disabilities, there’s a lot that Canada simply doesn’t know about itself.
Consider that we don’t have a clear national picture of the vaccination rate in particular towns and cities. We don’t know the Canadian marriage or divorce rate. We don’t know how much drug makers pay the Canadian doctors who are charged with prescribing their products. We don’t have detailed data on the level of lead in Canadian children’s blood. We don’t know the rate at which Canadian workers get injured. We don’t know the number of people who are evicted from their homes. We don’t even know how far Canadians drive – a seeming bit of trivia that can tell us about an economy’s animal spirits, as well as the bite that green policies are having.
Our ignorance is decades in the making, with causes that cut to the heart of Canada’s identity as a country: provincial responsibility for health and education that keeps important information stuck in silos and provides little incentive for provinces to keep easily comparable numbers about themselves; a zeal for protecting personal privacy on the part of our statistical authorities that shades into paranoia; a level of complacency about the scale of our problems that keeps us from demanding transparency and action from government; and a squeamishness about race and class that prevents us from finding out all we could about disparities between the privileged and the poor.
But if the problem has deep roots, it has never mattered more. We live in a data-driven age, when the internet and the processing power of computers has made it easier than ever to hoover up statistics about a society, make them public and accessible, and crowdsource better decisions about how to deliver everything from income support to green incentives to job training. Governments around the world have harnessed that power to make themselves smarter, leaner and more effective.
…
But government data are a different thing. It’s the information that various ministries, agencies and bureaus collect about citizens through administrative sources – such as tax filings and birth records – and questionnaires such as the census and community surveys. And unlike the tech companies that probe our digital lives for profit, governments aren’t in the business of caring what the numbers say about us individually: They’re looking for patterns.
The best way to spot trends is to enlist the public’s help by making your data open. At its best, this produces a charmed cycle: The government collects numbers, makes them anonymous and puts them on a website; a researcher, or even an ordinary citizen, notices something in the numbers (a spike in deaths! or a decline in productivity!); the government hears the alarm and can begin figuring out ways to address the problem.
….
In Canada, though, this cycle too often breaks down. Either the government hasn’t collected the relevant numbers or it won’t make them public. Important questions go unanswered. That’s especially dangerous for Canadian patients: Our health-care system is pockmarked with data gaps that leave people unsure of the quality and integrity of the care they’re getting, and leaves us in the dark about whether the system is meeting people’s needs.
….
No one asks themselves that question more often than academics. They are patient zero for Canada’s data-gaps epidemic. And the frustration they experience has implications for us all: When scholars work without access to proper data, they are unable to tell us stories about our world and ourselves that can only be unearthed when expert analysis is applied to a thorough rendering of the raw facts.
Lindsay Tedds, a professor of economic policy at the University of Calgary, has been struck recently by the difference, between the United States and Canada, regarding one of the most fundamental subsets of demographic data: birth records.
To begin with, the standard U.S. certificate of live birth collects all kinds of detailed information about the child’s parents – particularly their level of education and their race. “We know that African-American women die in childbirth at an alarming rate. We know that non-white babies are born smaller and earlier,” says Prof. Tedds. “Both of these factors are highly related to [the] poverty of the parents.” In Canada the picture is far less clear. “Imagine,” she says, “if we had similar detailed, population-level data, including for pregnancy and birth outcomes, for Indigenous moms.”
But even if the records were more detailed, she notes, the information would be harder to dig out: “The United States birth data, you just go onto a website and download it.”
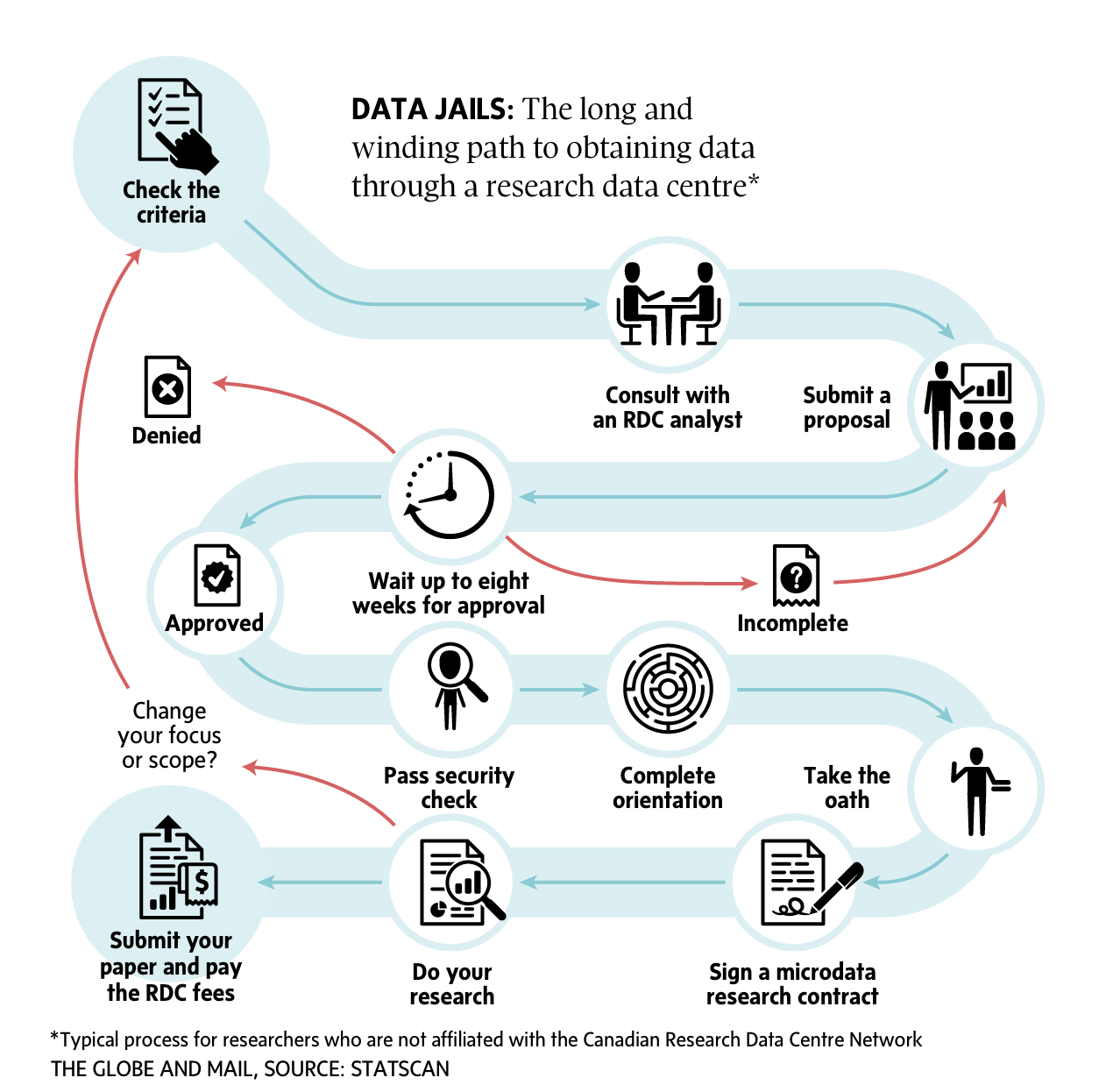
In Canada, by contrast, birth data are kept in a series of facilities called Research Data Centres – the bane of many researchers trying to unlock tricky problems in Canadian social science. Statistics Canada opened the first RDC in 2000, with the aim of giving researchers access to so-called confidential microdata – the previously hidden guts of Statscan’s collections, such as census responses, health-survey results and birth records – without compromising anyone’s privacy.
But while they contain a rich trove of data, the fact that it is embedded with potentially identifying details about individual Canadians – not names, which are scrubbed ahead of time, but occupation and gender, for example – means that researchers must jump through a series of bureaucratic hoops before they can get their hands on it. Wendy Watkins, a Carleton University sociologist and former Statscan analyst, calls the centres “little data jails.”
There are 30 RDCs across Canada, almost all on university campuses – although Brandon, Sudbury, Trois-Rivières, Charlottetown and Peterborough, Ont., all university towns, have no such research centres. There are no RDCs at all in Nunavut, Yukon or Prince Edward Island. Because researchers have to visit them in person, that often means travelling hundreds of kilometres.
And that journey only gets them to the jailhouse gates. Then the real hurdles emerge. These can include providing a five-year address history, submitting a research proposal well ahead of time, and being formally sworn in as a government employee for the duration of your visit, complete with a legally binding oath of secrecy. If you are not a graduate student or university faculty, you’re likely to face more than a dozen steps before being able to actually publish your research. In some cases, researchers have to pay a sizable fee – routinely more than $5,000 – to access the information.
“I had to get fingerprinted,” says Prof. Andersen of Western, “even though I had my passport. What did they think, I was faking my passport?”
In other countries, the kind of data we keep cloistered in RDCs for privacy reasons is often simply scrubbed of identifying details and opened to the public. Says Calgary’s Prof. Tedds, “We know enough about how to censor and anonymize data that those concerns … they shouldn’t be concerns.”
Placing the burden of security onto individual researchers, in turn, means that reams of information, painstakingly gathered by our government and waiting to be sorted, distilled and interpreted – and, possibly, put to use improving Canadian lives – remain untapped. “I’ve had a few colleagues tell me they don’t study Canada because it’s too much of a pain in the neck,” Prof. Siddiqi says. “Of course I also want to study Canada, but at a certain point you have to throw your hands up.”
The recent controversy over Statscan’s plan to request customers’ personal financial data from Canadian banks might have given the impression of an outfit with a cavalier attitude toward privacy. In fact, the episode was deeply out of character for the agency. Typically, Statscan suffers from the inverse problem, what former assistant chief statistician Michael Wolfson calls “excessive privacy chill.”
The secrecy, bureaucracy and plain eccentricity that have come to characterize the country’s central data-gathering agency are far from unique among federal departments and ministries. Almost every one of them gathers and publishes its own significant stores of data – and Canada’s Auditor-General has spent years quietly pointing out how badly they tend to manage the task.
Glenn Wheeler, a principal in the federal watchdog’s office, says ministries often don’t gather enough data about their own policies to have a good sense of whether those policies are working – or don’t release enough data to convince the public, which is paying for the programs through tax dollars. “It’s a serious issue we find across our audits, across departments, across a number of years,” he says.
What Mr. Wheeler doesn’t mention, but is hard not to notice, is the number of data gaps that threaten to undermine policies the government of Justin Trudeau has put a lot of stock in – policies meant to address such issues as sexual abuse, the settlement of refugees and improving the lot of Indigenous Canadians. “Good policy is impossible without good data,” said Finance Minister Bill Morneau in a 2016 speech. But this government’s trademark policies often don’t have good data behind them.
In an audit of the Canadian Armed Forces released last fall, the auditor-general found that the military had “no centralized system to collect and track incidents of inappropriate sexual behaviour in a systematic way,” despite launching Operation Honour to combat sexual misconduct in its ranks in 2015. An Armed Forces spokesperson told The Globe that the military is now addressing the issue: a sexual-misconduct tracking system was “implemented” this past October and it will be “fully operational” some time in 2019.
Meanwhile, a 2017 study of the government’s efforts to settle Syrian refugees – one of the Trudeau government’s signature initiatives – found that Immigration, Refugees and Citizenship Canada was not gathering numbers on such key measures as the average number of months those refugees spent on income assistance, the effectiveness of the language training they have received, or the percentage of refugee children attending school.
….
As the benefits of open government data become more widely accepted, Canada is falling behind many of its peer countries in making use of the stuff. Ireland publishes a comprehensive biennial data set on the well-being of children; Denmark tracks every aspect of gender equality; Britain breaks down many social-welfare indicators by ethnicity; and Australia publishes national workplace-injury rates – none of which can be said of Canada.
But no country throws our data failures into starker relief than does the United States. You might expect our southern neighbours to be data laggards: After all, theirs is a country that tends to prefer small government and emphasize individual rights over the common good.
Instead, Americans are world leaders at gathering and sharing an abundance of national numbers. “The U.S. has awesome data on almost everything,” says Jennifer Winter, director of energy and the environment at the University of Calgary school of public policy.
Some attribute U.S. public-data excellence to the country’s (small-r) republican form of government, which treats government property as the people’s. But it’s not just a question of national DNA. The United States has made strides in recent years as a result of deliberate government policy.
In 2013, then-president Barack Obama signed an executive order making government data open and machine-readable by default – a move which, remarkably, Donald Trump signed into law just this month after being presented with a bipartisan bill giving Congressional approval to the broad strokes of president Obama’s order.
During his tenure, Mr. Obama also hired Silicon Valley whiz D.J. Patil as the country’s chief data scientist. Mr. Patil’s marching orders: to free up more of the information that had been mouldering, unseen and unused, in federal government vaults. He realized, in short, that the country could solve more of its problems if it had more eyeballs trying to identify them. “Through these data sets, you get brilliant insights,” he says. “We’re harnessing the power of the country’s entire knowledge base.”
Embedded in Mr. Obama’s health-care law, meanwhile, was a sunshine list for payments made by drug companies to doctors. The data helped reveal some chastening facts. Among them: The more money the average doctor receives from opioid makers, the likelier she is to prescribe opioids; and even such small gifts as a single meal tend to tilt doctors toward prescribing more expensive brand-name drugs.
That analysis would not be possible in Canada; the numbers aren’t there. (Under its previous Liberal government, Ontario was on the verge of forcing pharma-payment disclosure, but the program has been put on hold by Doug Ford’s Conservatives.)
A disarming number of people who have spent time thinking about the problem come to the same conclusion about why this is: Yes, federalism creates data silos, and yes, Statscan is too risk-averse and cash poor, and yes, provinces and federal departments have a built-in incentive to keep their failures hidden with data blackouts. But maybe, just maybe, the problem has even deeper cultural roots. Maybe we’re just not curious enough about what goes on within our borders – blissful in our ignorance. Maybe, these people suggest, the problem comes down to Canadian complacency.
Tellingly, Canada’s Copyright Act, signed in 1921, gave the Crown the rights, for a full 50 years, to any work produced by any government department – a stark contrast with our southern neighbour, which banned government copyright in the 19th century. “The U.S., in its early history, made legislation that said, ‘We shall make this information available to the people,’ ” says Mark Leggott, executive director of Research Data Canada, a non-profit that helps researchers use public data. “In Canada, we made it so that the information was the property of the Queen.”
…
It doesn’t have to be this way. The Liberals’ 2015 election platform promised to “embrace open data” and stated that a Liberal government would “make government data available digitally, so that Canadians can easily access and use it.”
And, to be fair, the Trudeau government has certainly made some progress over the past three years. Most famously, it reinstated the mandatory long-form census, which Stephen Harper’s Conservatives had axed in 2010.
A spokesperson for Jane Philpott, the minister of digital government, a portfolio recently created and tacked on to the Treasury Board, also noted that 81,909 data sets are available through the federal open-government portal (though many of those were published by previous governments). Anyone can now open their laptop and look up everything from Canada’s sulphur-oxide emissions, over time, to the country’s “spatial density of oats cultivation.”
Like the governments of every industrialized country, Canada posts far more data online than anyone would have thought possible 30 years ago. It actually tied for first with Britain in a recent “open-data barometer” created by the World Wide Web Foundation (though it’s worth noting that the ranking awards points for fairly basic achievements, like publishing government budgets and election results, and that Canada scored poorly on national environmental statistics).
Statistics Canada would like you to know that it is making progress, too. Anil Arora, the agency’s chief statistician, points to new technologies and techniques that are changing the way it collects public data. Last year, for instance, the agency crowdsourced black-market cannabis prices by asking the public to use an app called StatsCannabis. More than 20,000 people responded. Statscan is also experimenting with “virtual data research centres” that will make microdata more easily accessible by computer, although their inauguration is likely years away.
Notwithstanding the backlash to Statscan’s banking-information scheme – and anxiety in some quarters about giving government more power to gather the personal information of citizens – the public has also shown signs of embracing the value of government data in recent years. The cancellation of the 2011 mandatory long-form census had the unexpected consequence of raising the census’s profile, and maybe even its popularity. The 2016 response rate was the highest ever, at 98.4 per cent, suggesting that Canadians see taking part in data collection as their civic duty, provided their confidentiality is protected and they feel it’s for the public good.
To be sure, a problem as vast and diffuse as a country’s ignorance about itself can hardly be laid neatly at one government’s door, much less one ministry’s. Still, given the Liberals’ enthusiasm for evidence and openness, their reluctance to frankly admit that Canada has a data deficit and to propose concrete solutions is notable.
When asked to comment for this story, the Prime Minister’s Office deferred to the minister of digital government, whose spokesperson’s answers focused on the government’s achievements, especially relative to the Harper Conservatives, and who spoke in general terms about plans for more data openness in the future. For example, in response to a question about the dozens of data gaps identified by The Globe, the spokesperson replied, “We have reinstated the long-form census, unmuzzled government scientists, and made ministerial mandate letters public while tracking progress on those commitments to Canadians. We know there is always more work to do.”
The leaders of Statscan were also reluctant to take ownership of Canada’s data-gap problem. In an interview last year, Mr. Arora pointed a finger at academic researchers who are unable to ferret out the numbers they need. “I would argue that there’s still a lot of data that we have that either researchers don’t even know about or underutilize,” he said. “They find the vetting steps, the confidentiality component, to be a little too much for them.”
In the meantime, Canadian public data remains full of lapses, hesitations and holes – for things as basic as average wait times for mental-health services and the number of homeless people who die on our streets. And the data we have is often so hard to access, it might as well be hidden. Even Mr. Arora knows the dangers of asking the country to fly blind this way: “There could come a day when the population says, ‘You had access to all of these data stores and you could have reasonably used it to prevent something nasty from happening. Why didn’t you?’ ”
Mr. Arora posed his question as a hypothetical – but didn’t need to. Every day, Canadian governments have the chance to prevent nasty things from happening, by putting stark numbers in front of Canadians, so that the public can demand change where it’s needed and build on what the country is doing right. And every day, governments pass up the opportunity to do so. On maternal health, on Indigenous education, on environmental action, on the safety of drugs and the integrity of the doctors who prescribe them, on matters as seemingly mundane as how far Canadians drive and as patently urgent as the rate at which whole demographic groups are dying, governments deprive Canadians of the data needed to make good decisions. Every day, they leave Canadians in the dark.