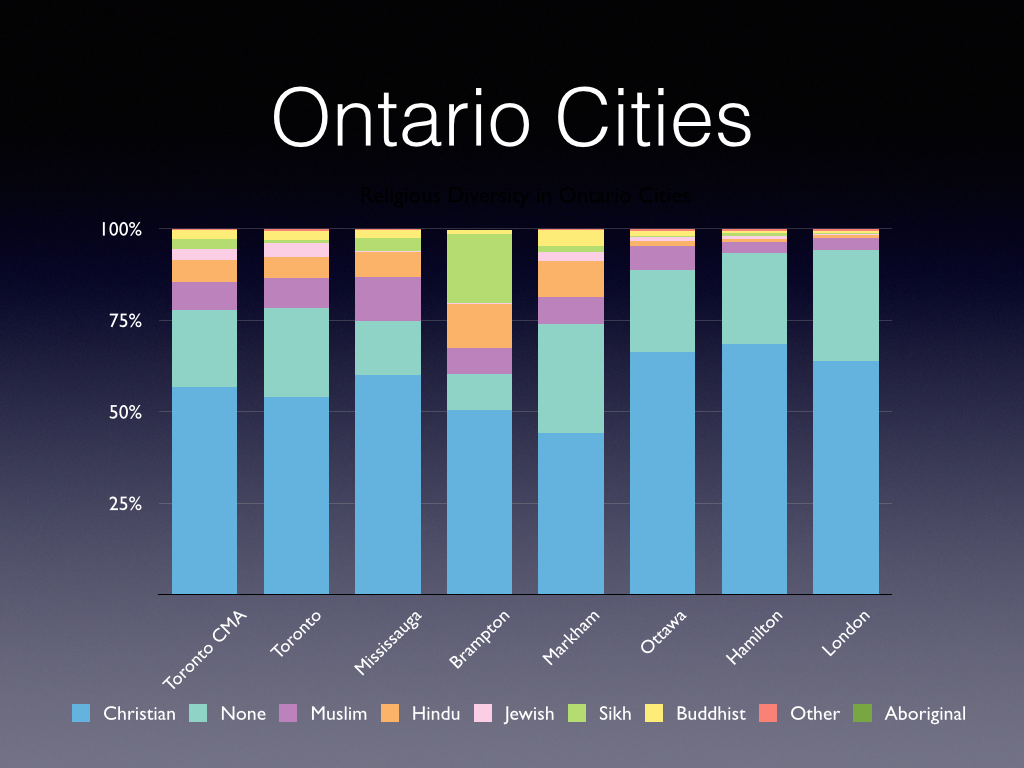
Fun example of innovative analysis (and for all those of you who claim to read Piketty or other similar tomes):
Jordan Ellenberg, a mathematician at the University of Wisconsin, Madison, has just about proved this suspicion correct.
In a cheeky analysis of data from Kindle e-readers, Mr. Piketty’s daunting 700-page doorstopper emerged as the least read book of the summer, according to Prof. Ellenberg, who calls his ranking the Hawking Index in honour of Mr. Hawking’s tome, famous as the most unread book of all time.
As a result, he is tempted to rename it the “Piketty Index,” because Mr. Piketty scored even worse than Mr. Hawking.
As such, both stand as extreme case studies in aspirational reading. Like the Economist magazine’s Big Mac index of hamburger prices around the world, which is both silly and serious, Prof. Ellenberg’s Hawking Index is funny, in that it reveals the vanity of many book choices. But it also offers an interesting psychological perspective on reading that is born of good intentions, and dies of boredom on the dock or beach.
The calculation is simple, and as Prof. Ellenberg says, “quick and dirty.” It exploits a feature of Kindle that allows readers to highlight favourite quotes. It averages the page number of the five most highlighted passages in Kindle versions, and ranks that as a percentage of the total page count. Although it does not measure how far people read into a book, it makes a decent proxy for it.
“Why do you buy a book? One reason is because you know you’re going to like it,” Prof. Ellenberg said. “Another reason might be, ‘Oh, I think this book will be good for me to read.’”
….. He said his formula illustrates what mathematicians call the problem of inference, meaning he cannot say for sure these books are going unread, just that he has strong evidence for it.
“You can make some observation about the world, but there’s some underlying fact about the world that you’d like to know, and you want to kind of reverse engineer. You want to go backwards from what you observed to what you think is producing the data you see,” he said.
Other books reveal different insights into why people buy books they start but do not finish. Michael Ignatieff’s political memoir Fire And Ashes, for example, scores comparatively well for non-fiction at 44%, far better than Hillary Clinton’s Hard Choices, which barely cracked 2%. Lean In, the self-help book by Facebook executive Sheryl Sandberg, scored 12.3%.
In fiction, The Luminaries, by Canadian-born New Zealand author Eleanor Catton, which won last year’s Man Booker Prize, scores a mere 19%, and would score a lot lower if not for one highlighted quote near the end.
Prime Minister Stephen Harper’s book on hockey, A Great Game, curiously has no highlighted passages, so cannot be ranked on the Hawking Index (or, equivalently, ranks as low as is theoretically possible).
Fiction tended to score higher, likely reflecting the tendency for non-fiction authors to put quotable thesis statements in the introduction. The only novel that was down in the range of the non-fiction books was Infinite Jest by David Foster Wallace.
Prof. Ellenberg does not mean to disparage the low ranking books, he said, noting that the reason people buy them in the first place is that they are rich in content.
“I think it’s good to do back of the envelope computations as long as you do them with the appropriate degree of humility, and understand what it is that they’re saying,” he said. “I think any statistical measure you make up, you take it as seriously as it deserves to be taken.”